The race for Artificial General Intelligence (AGI) has hit a bottleneck: efficiency. Standard Large Language Models (LLMs) are “computationally heavy” because they don’t know how to separate thinking from remembering.
A groundbreaking research paper from Peking University and DeepSeek-AI—“Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models” (arXiv:2601.07372)—is changing the paradigm. By introducing a “Conditional Memory” system called Engram, they have effectively given AI its own version of the human hippocampus.
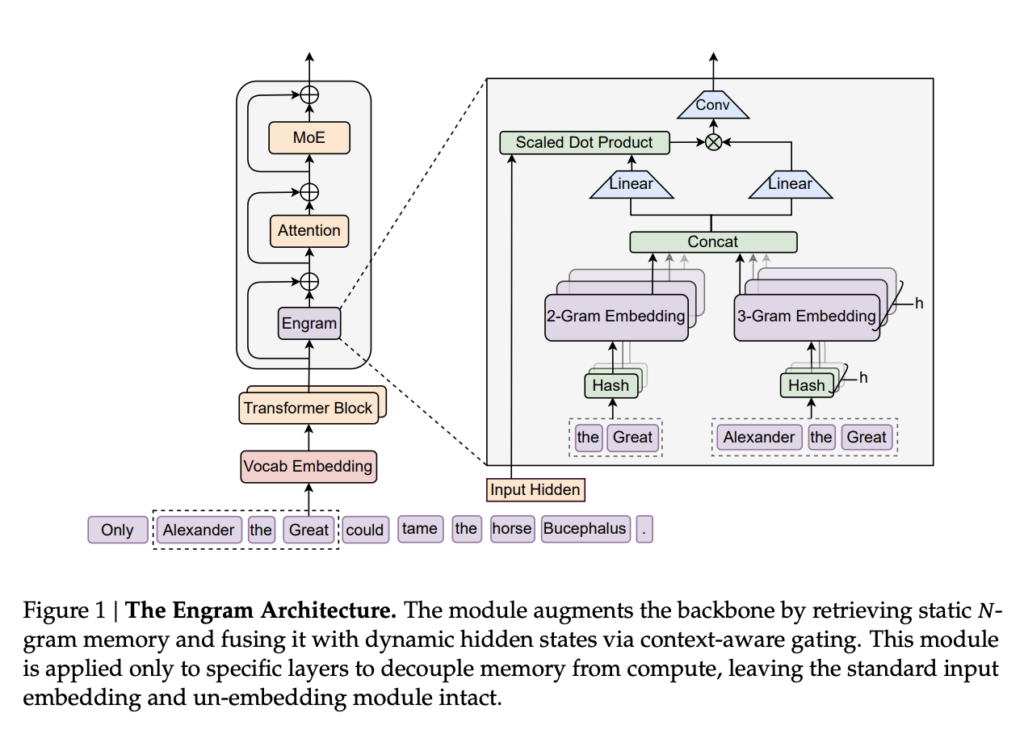
What is the Engram Module in AI?
In neuroscience, an “engram” is a unit of cognitive information—a memory trace. In this new AI architecture, the Engram module acts as a massive, scalable lookup table.
Currently, models like GPT-4 or Claude use “Conditional Computation” (Mixture-of-Experts) to handle both logic and facts. DeepSeek’s innovation introduces a second axis of sparsity: Conditional Memory.
Instead of forcing a neural network to “calculate” a fact, the model uses an O(1) lookup to retrieve it instantly. This mimics Dual-Process Theory in humans:
- System 1 (Fast): Retrieval of known patterns via Engram.
- System 2 (Slow): Deep reasoning via the Transformer layers.
Key Stats: Why Engram Outperforms Standard MoE
When the researchers scaled the Engram module to 27 billion parameters, the performance gains were undeniable. By freeing the “reasoning neurons” from the burden of memorization, the model achieved massive jumps in benchmarks:
Benchmark Performance Gains:
- General Reasoning (BBH): +5.0 points
- Factual Knowledge (MMLU): +3.4 points
- Scientific Problem Solving (ARC-C): +3.7 points
- Coding (HumanEval): +3.0 points
- Mathematics (MATH): +2.4 points
The U-Shaped Scaling Law: The “Goldilocks Zone” of AI
One of the paper’s most significant contributions is the discovery of the U-Shaped Scaling Law. The researchers found that you can’t just add infinite memory or infinite computation. There is an optimal balance.
The study suggests that allocating roughly 20-25% of a model’s sparse parameter budget to “Conditional Memory” (Engram) provides the maximum possible intelligence per FLOP.
Why This Matters for the Future of AGI
The most exciting part of this research isn’t just the accuracy—it’s the efficiency.
- Lower GPU Costs: Because Engram lookups are deterministic, they can be stored in standard CPU RAM rather than expensive GPU VRAM.
- Ultra-Long Context: By delegating local patterns to memory, the model’s attention mechanism can focus on global context. This improved Needle In A Haystack (NIAH) scores from 84.2 to 97.0.
- Scalability: We can now build models with trillions of “knowledge parameters” without needing exponentially more power.
Conclusion: A New Era of Sparse Intelligence
DeepSeek’s Engram paper proves that the path to AGI isn’t just about making models bigger—it’s about making them smarter by mimicking the modularity of the human brain. By separating Conditional Memory from Conditional Computation, we are finally allowing AI to “know” things as effortlessly as we do.
Is the Engram module the missing piece of the AGI puzzle? Share your thoughts in the comments below!