LLM based autonomous agents can use Generative AI to automate processes without needing human intervention. There is a subtle distinction between autonomous agents and workflows as explained in this anthropic blog. If you know the series of steps needed to automate a process, then you can use a workflow. However, if you need a system to figure out the series of steps required to automate the process, then that’s autonomous agents. In this blog we will look at the different parts of autonomous agents and a mental model on how to start thinking about agents when you have a business problem.
Why LLM based autonomous agents?
‘I have heard about LLM based autonomous agents and want to start using this cool thing… ‘
‘I have a business goal of improving our NPS/CSAT/CES scores by 20% by end of this year, can Generative AI help me?’
If you think about the two questions above, it becomes apparent that the reason for using LLM based autonomous agents should be more than a technical one. If you are on your first Generative AI project, make sure you think about the why before you think about the how.
Components of LLM based autonomous agents
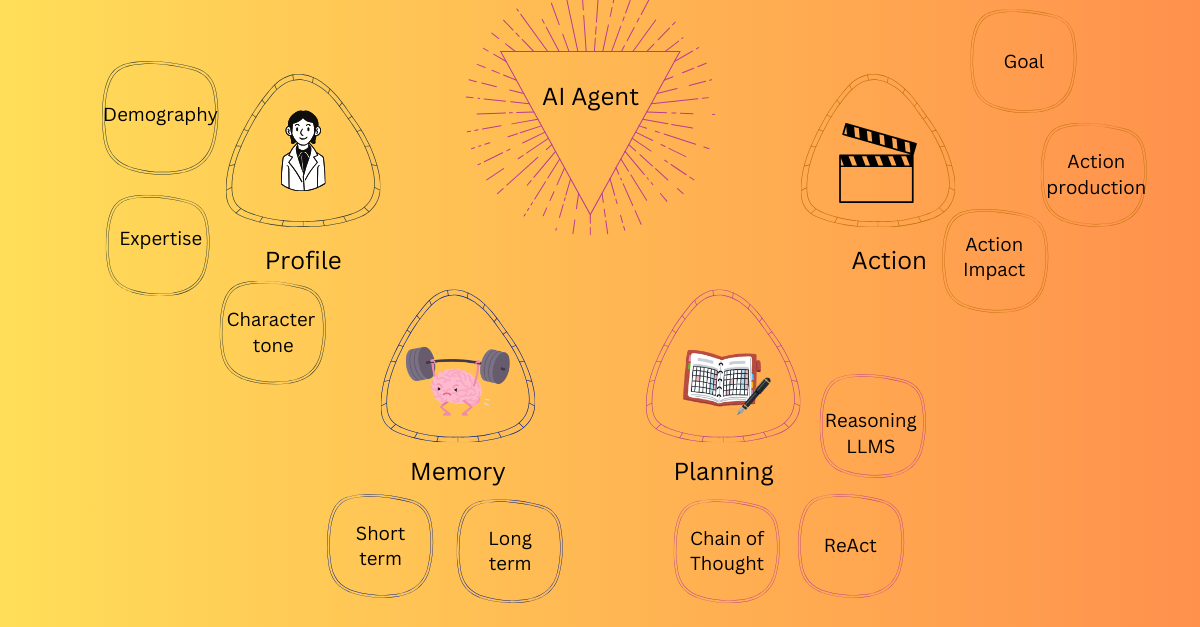
Once you have defined your business problem and are ready to build your autonomous agent, there are four components that you might have to start thinking about. This blog will only cover the concepts, and in the next blog we will look at the implementation.
Give your agent a character profile
If you think of a business workflow then there are multiple personas that come together to accomplish a task. For example, if you are building a mortgage processing system, then you might have a person looking at the customers document, another person that looks at the credit score, someone else that looks at the property and so on. Each person has a set of tools that they have access to to accomplish their task. While building an agentic system too, you will need to create agents that have a profile and has access to specific tools.
We will talk about tools later, but let’s talk about the profile first. To give the agent a profile, write a prompt the provides information such as demography (age, gender etc), expertise (credit score specialist), social information (relationship of this agent with other agents), character (“you are an outgoing person”), tone(“use a professional but friendly language”). You can either handcraft the profile manually, or you can even use an LLM to do that for you. Here’s a paper that introduces a simulator called RecAgent to build an agent that simulates behaviours.
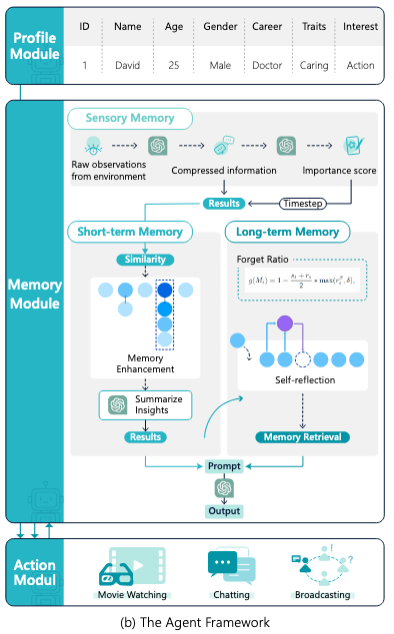
An image from the RecAgent paper that introduces how to build agents that simulate a profile.
A technique to align the agent profile closer to a human profile would be to use profiles from demographic databases such as the census or American National Election Studies.
Give your agent memory
There is nothing more frustrating for a customer than repeating what they have already told an agent. If you build LLM based agents that can’t remember what their customers told them a few seconds or a few days ago, then you won’t get anywhere near your target NPS score. A thing to understand though is that LLMs, by default, cannot remember conversations. Each call to an LLM is stateless. The LLM has no way to remember previous conversations, unless your replay the whole conversation every time. There has been some research around building LLMs with inherent memory, but that’s still not available. How do you give agents memory then?
Before we talk about the how, lets understand the types of memory that the agent would need. The agent would need both short term and long-term memory. For example, an agent’s profile is its long-term memory, but a current conversation would sit in its short-term memory.
The quickest way to implement both the short-term and long-term memory would be to pass all previous conversations via the prompt. This is not a bad idea for many use cases. If the conversations are only a few sentences long, then we can store all the conversation in memory (temporary or permanent) and play the entire conversation back in each call to the LLM. There are, however, certain disadvantages to this approach. As the conversation history grows, the calls to LLM can become expensive (the more tokens you pass in, the more money you pay) and slower. There may also be limits to the number of words that your LLM can take as input. Also, as the context length grows, the LLM may struggle figuring out which part of the past conversation is more meaningful in the current context.
To overcome the shortcomings of short-term memory, you can ‘attach’ a long-term memory module to the agentic system. For example, you can store the previous conversation in an external system (such as a vector store or a database) and retrieve parts of the previous conversation that are relevant to the current conversation. For example, if a customer is talking to an agentic bot, then the bot can retrieve the previous conversation relating to the current customer case and ignore all conversations that refer to a different case. In addition to retrieving part of previous conversations, long term memory can also store a summary of previous conversations. For example, you can store information about the customer sentiment during the previous conversations (irrespective of the case number or whether the customer used the bot or sent an email) and retrieve the sentiment from the long-term memory. This will allow you to modify the agent responses to be more aligned to customer expectations. To make retrieval from long-term memory more effective, you can use an RAG system to retrieve relevant information from long-term memory.
There are different ways to store memory, and each has their pros and cons:
- Store as natural language text in its original form.
- Store as embedded vectors.
- Store as a summary of previous conversations.
- Store memory in a hierarchical structure or temporal structure.
The different ways are not exclusive. It’s also possible to have a combination of these.
When retrieving memory during a conversation, it’s important to extract meaningful information using criteria such as recency, relevance and importance. While writing memory it’s important to remove memory duplication, or to remove/compress information in memory if it reaches a certain size. It’s also important to periodically reflect on the existing memory and 1/ summarize it 2/ extract abstract information from it (for example, sentiment).
Help your agents plan better
When we need agents to decide on what series of steps it should take, then we want them to be able to plan their next steps. We will look at different planning methods in a single agent. However, in a multi-agent scenario, there will be a single ‘orchestrator’ agent that does most of the planning.
- Chain of Thought – In this method, we pass in reasoning steps within the prompt itself. The LLM then uses the steps as an example to create its own steps when it receives user input. We can also tell the LLM to ‘think step by step’ without providing any specific examples. This is called zero COT.
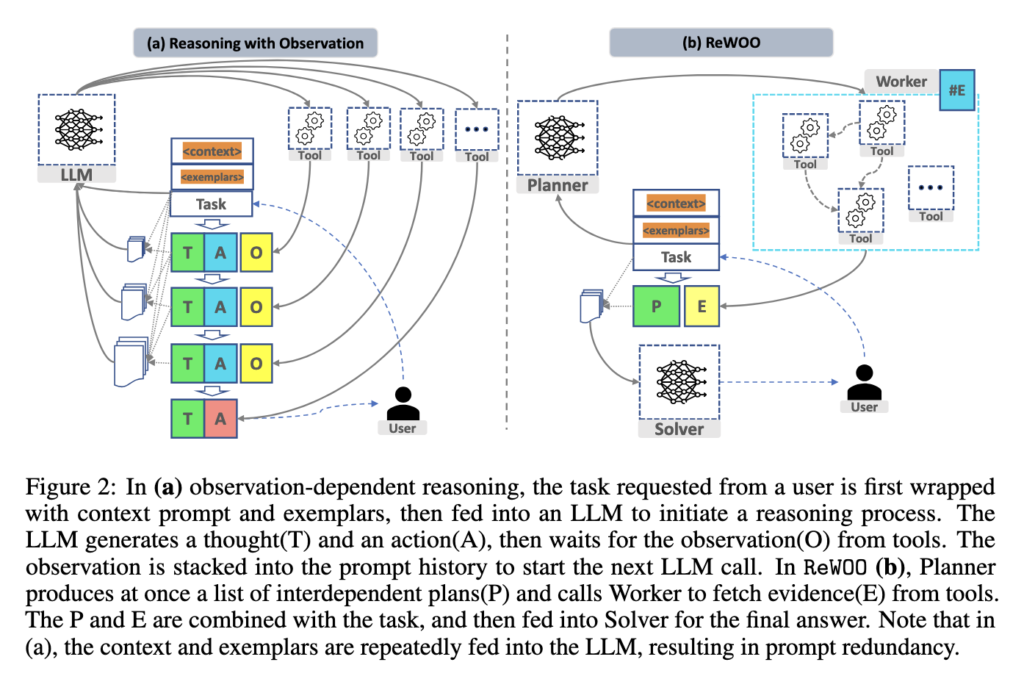
- ReWOO – This method introduces a concept where the reasoning is separated from the observation. Normally, the LLM would wait for the response from each step before executing the next step.
3. SwiftSage – If you have read the book by Daniel Kahneman called ‘Thinking, Fast and Slow’ then you know exactly what SwiftSage does. It is composed of two modules a/Swift replicates the fast and intuitive thinking process and b/ Sage uses reasoning LLMS for planning and grounding.
4. Self-consistent CoT (CoT-SC) – Here the LLM samples a diverse set of reasoning paths. Instead of jumping straight to the first solution that comes to mind, it explores multiple different ways of solving the problem, then picks the final answer that best matches across all these different solution approaches. Think of it like getting multiple opinions from different experts and choosing the answer that most of them agree on, rather than just going with the first expert’s suggestion.
5. Tree of Thoughts (ToT) : ToT is an improved version of Chain of Thought that lets LLMs consider multiple possible paths to solve a problem, similar to how humans might explore different solutions on a decision tree. Unlike the simpler Chain of Thought which follows a single linear path, ToT can evaluate different options at each step, look ahead to future consequences, and even backtrack if it realizes a different path might work better.
6. ReAct : Instead of treating an LLM’s ability to reason and its ability to take actions as separate skills, this approach combines them – letting the LLM think and act at the same time. This creates a more natural flow where the LLM can adjust its plans based on what it learns from taking actions, and can use its reasoning to decide what actions to take next – similar to how humans naturally blend thinking and doing when solving problems.
7. Voyager, Ghost, LLM-Planner are few other techniques that use feedback mechanism
Time to take action
Once the agents have planned their execution, its time to take action now. The actions can be in the form of calls to external systems such as web or API. The action has three dimensions
- Goal : The intented outcome of the action. This could be
- Task completion: accomplish specific tasks such as completing a function in software development.
- Communication: The action is to communicate with other agents or with humans. e.g. In a multi-agent collaboration system has agents that coordinate tasks
- Action Production: The agent can perform the actual action using
- Memory recollection : An action could be via extracting short term or long term memory.
- Predefined plans: An action is performed via a predefined plan or via goal decomposition to create sub-goals
- External tools : An action is performed via external tools such as APIs, databases and knowledge bases (SQL to query databases) and external models
- Action impact: The consequence of an agents action can be to
- Change environment by calling external tools. i.e. moving a chess piece
- Change internal state i.e. updating memory, creating new plans etc
- Trigger new action
Conclusion
Building LLM-based autonomous agents requires careful consideration of four key components: character profiles, memory systems, planning capabilities, and action mechanisms.
Think of these components as building blocks:
– Character profiles give your agents purpose and personality
– Memory systems enable contextual understanding and continuity
– Planning capabilities help agents navigate complex decisions
– Action mechanisms allow agents to effect real change
As we move forward in the age of AI, autonomous agents will increasingly become part of our business workflows. However, their effectiveness will depend not just on the sophistication of the underlying LLMs, but on how well we design these fundamental components to work together in solving real business problems.